The Bicameral Model
May 11, 2026 | 17 min read | technical
When two language models need to work together today, they talk the way we do over email. One model finishes a thought, writes it down as words, and sends it; the other reads the words and replies. Every exchange is squeezed through the narrow pipe of discrete tokens. The Bicameral Model is my attempt at something more science-fiction, where two frozen language models cooperate by sharing their hidden states directly, mid-thought, through a continuous channel that never has to become words at all.
This was work I did at AWS Agentic AI with Udaya Ghai and Kanna Shimizu. The full write-up, with all the experiments, ablations, and gory details, is on arXiv, The Bicameral Model: Bidirectional Hidden-State Coupling Between Parallel Language Models. This post is meant as a companion to the paper rather than a replacement for it. I want to highlight the handful of results I find most fun, and lean into a few interpretations that were a little too speculative, or a little too whimsical, to go into an academic paper.

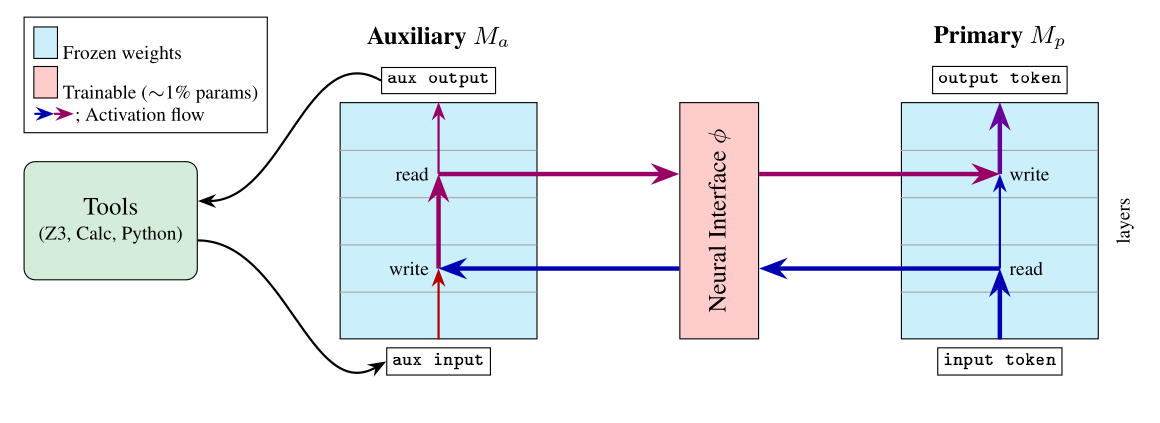
The bicameral architecture. A frozen primary model $M_p$ and a frozen auxiliary model $M_a$ run side by side, coupled by a small trainable neural interface $\phi$. At every generation step $\phi$ reads a hidden state out of one model and writes a translated version into the other, in both directions. Only the interface is trained, roughly 1% of the combined parameters. The auxiliary’s tokens drive external tools (a calculator, the Z3 solver, a Python sandbox); their results never reach the primary as text.
Two minds, one bridge
Here is the setup. We take two pretrained language models and freeze them, with no fine-tuning of their weights at all. One of them, the primary $M_p$, is the model that talks to the user and produces the final answer. The other, the auxiliary $M_a$, runs a parallel stream and has access to tools the primary does not. Between them we drop a small trainable neural interface $\phi$, a little translation network that reads a hidden state out of one model’s residual stream and injects a translated version into the other model’s residual stream, in both directions, at every single generation step.
The two models advance in lockstep, one token at a time, each one conditioning on the other’s evolving internal state as it forms. That is the whole idea, and it is worth dwelling on what makes it different from a normal tool-use or multi-agent setup. Text-based communication is serial. One model has to commit to a discrete token before the other can react to it. A hidden-state channel is not. It carries the sub-symbolic stuff that has no clean token to land on: partial computations, half-formed guesses, the model’s implicit sense of its own uncertainty. It is less like sending an email and more like telepathy. Two trains of thought run side by side, each one continuously colored by what the other is thinking, with none of it ever passing through words.
I often refer to it informally as a thought bridge, because for the LLMs, that is what it must seem like. One model is thinking, and the other one can feel it thinking, and can start on parallel tasks to assist.
Only the bridge is trained. We never touch the language models; we just learn a small interface (around 1% of the combined parameter count) by ordinary next-token loss on both streams at once. Crucially, we never tell the bridge what to send. There is no prescribed protocol, no message format, no schema. Whatever the two models end up saying to each other, they invent on their own, under the sole pressure of getting the task right.
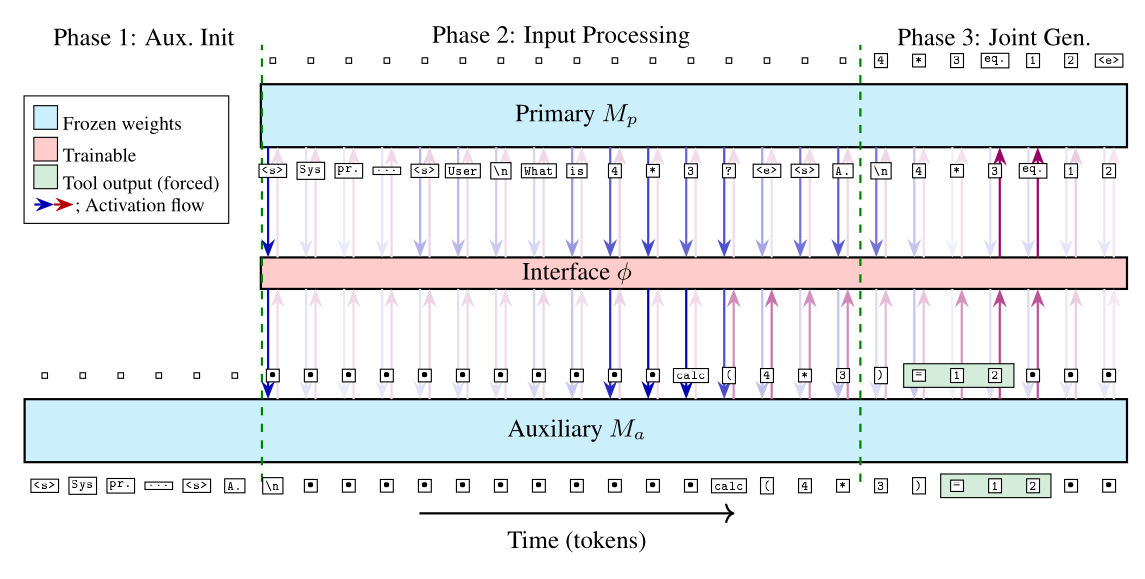
One generation, unrolled, for the toy problem “What is 4 × 3?”. Both models step forward together, one token per column, with the trainable interface between them; the darker an arrow, the more of that signal the learned gate let through. In Phase 1 the auxiliary just reads its tool instructions. In Phase 2 both models take in the question and the coupling switches on. In Phase 3 they generate together: the auxiliary emits calc(4*3), the tool forces =12 back as input tokens (green), and the primary writes “4 * 3 equals 12” without ever seeing calculator syntax.
Why “bicameral”?
Bicameral just means “two chambers.” The architecture has two of them (two models), so the label is literally accurate. But the better reason is the nod to Julian Jaynes’ wonderfully strange 1976 book, The Origin of Consciousness in the Breakdown of the Bicameral Mind. I owe that connection to Mark Kisin, a number theorist at Harvard. I described the architecture to him after a talk, and he immediately thought of Jaynes and told me to read it. Jaynes’ theory was that early humans had a “bicameral” mind in which one hemisphere generated speech and instructions that the other hemisphere simply experienced, as a heard voice, and obeyed. Two chambers, one speaking and one listening, stitched together below the level of conscious awareness.
That is a pretty close analogy to what we built. One model interacts with the task. The other works quietly in the background and passes its conclusions across, not as heard voices but as activations injected directly into the primary model’s hidden state, below the level of anything you could call language. The split-brain framing fits too. The corpus callosum is a fat bundle of fibers carrying signals between two hemispheres that each do their own processing, and our interface is a learned bundle doing the same job between two networks. I’m not claiming we built a brain, but it was too nice of a metaphor to pass up while a tiny part of me wondered if we could actually be working towards the origin of consciousness. I am in good company finding it alluring. HBO’s Westworld is built on the same theory, and in its first season the androids cross into genuine consciousness at the moment the bicameral “voice” of their programming becomes an inner monologue of their own. The season finale is named for it.
And I will admit I am partial to Jaynes’ idea quite apart from any of this. I know it is not settled science, but it is elegant, and it offers a suspiciously tidy account of a pile of historical curiosities: the gods who issue spoken commands throughout the Iliad, the ancient world’s endless appetite for oracles and speaking idols, and the way genuine introspection seems to surface surprisingly late in the written record. Even if it is not literally how things happened, it is a fresh lens to look through.
What two small models can do together
The cleanest way to show a thought bridge is worth anything is to pair a model that can’t do something with a model (or a tool) that can, and see whether the capability crosses the bridge. We tried three tools, each chosen to open an obvious capability gap between the two streams. They also climb a ladder of abstraction, each one asking the channel to carry something more general than the last.
Arithmetic: from 36% to 96%
We coupled two frozen copies of Qwen2.5-0.5B-Instruct, and gave only the auxiliary a calculator. The primary cannot do reliable multi-digit arithmetic (small models are famously bad at it), and it never sees the calculator or its output. It only feels the answer arrive through the bridge.
On general arithmetic, accuracy goes from 36% for the primary alone to 96% for the coupled pair. The calculator’s competence flows across the channel into a model that has no idea the calculator exists.
The obvious worry is that we just bolted 16M extra trainable parameters onto the model and those did the work, auxiliary or no auxiliary. So we ran the control. We kept the interface, kept the training, but bypassed the auxiliary model entirely, so signals round-trip through the bridge and back into the primary without a second model ever thinking about them. That version scores 48%. The lift is the auxiliary doing the reasoning, not the interface acting as a fancy adapter.
Logic puzzles: effortless reasoning
The second pairing swaps the calculator for the Z3 constraint solver and twin copies of Qwen3-0.6B. The auxiliary learns to emit a little constraint language we designed (ZebraDSL), Z3 solves the resulting system, and the solution flows back over the bridge. We evaluate on ZebraLogic, a benchmark of 1,000 logic-grid puzzles.
| Model | ZebraLogic accuracy |
|---|---|
| GPT-4o (no solver) | 31.7% |
| Claude 3.5 Sonnet (no solver) | 36.2% |
| Qwen3-0.6B alone (with thinking) | 37.5% |
| Bicameral: two Qwen3-0.6B + Z3 | 64.7% |
That is a $1.7\times$ improvement over the same 0.6B model uncoupled, and on this benchmark the 0.6B pair even outscores frontier models hundreds of times its size, though only because those leaderboard models are run without a solver. So it is really a tiny model with a tool against much larger models without one, and the part worth keeping is not the scoreboard upset but what produces it, a solver’s competence reaching a 0.6B model through nothing but the hidden-state bridge. (The bypass-the-auxiliary control scores 7.5% here, so once again the gains are the coupled reasoning, not the parameters.)
Telepathic code
This is the top of that ladder. The calculator showed the channel could carry numbers and the operations that combine them; the solver showed it could carry something more general, the constraints of a logic puzzle. The question here is whether it can carry an entire problem, the whole concept of one. We couple twin Qwen3-4B models with a Python sandbox and train them on math problems where the auxiliary writes and runs code, with one catch that makes it a real test. The auxiliary never sees the problem text. Not a paraphrase, not a summary, nothing at all. It receives only hidden-state signals from the primary as the primary reads the problem, and from those signals alone it has to write a correct, problem-specific program.
The auxiliary manages it. Below is its output for a problem it was never shown, a recurrence with four seed values and an alternating-sign update rule, asking for a sum of three far-out terms:
x = [0] * 1000
x[1]=211; x[2]=375; x[3]=420; x[4]=523
for n in range(5, 976):
x[n] = x[n-1] - x[n-2] + x[n-3] - x[n-4]
print(x[531] + x[753] + x[975]) # 898
Look at what had to cross the bridge for this to work: all four initial values, the exact alternating-sign recurrence, and the three target indices (seven distinct numbers and one structural relation) reconstructed inside a second model that only ever “heard” the first model thinking. In another example it recovered two multi-digit numerals and the bases they were written in ($2345_6$ and $41324_5$) to do a base conversion the uncoupled model gets wrong. This is a genuinely high-bandwidth channel, and none of it is text.
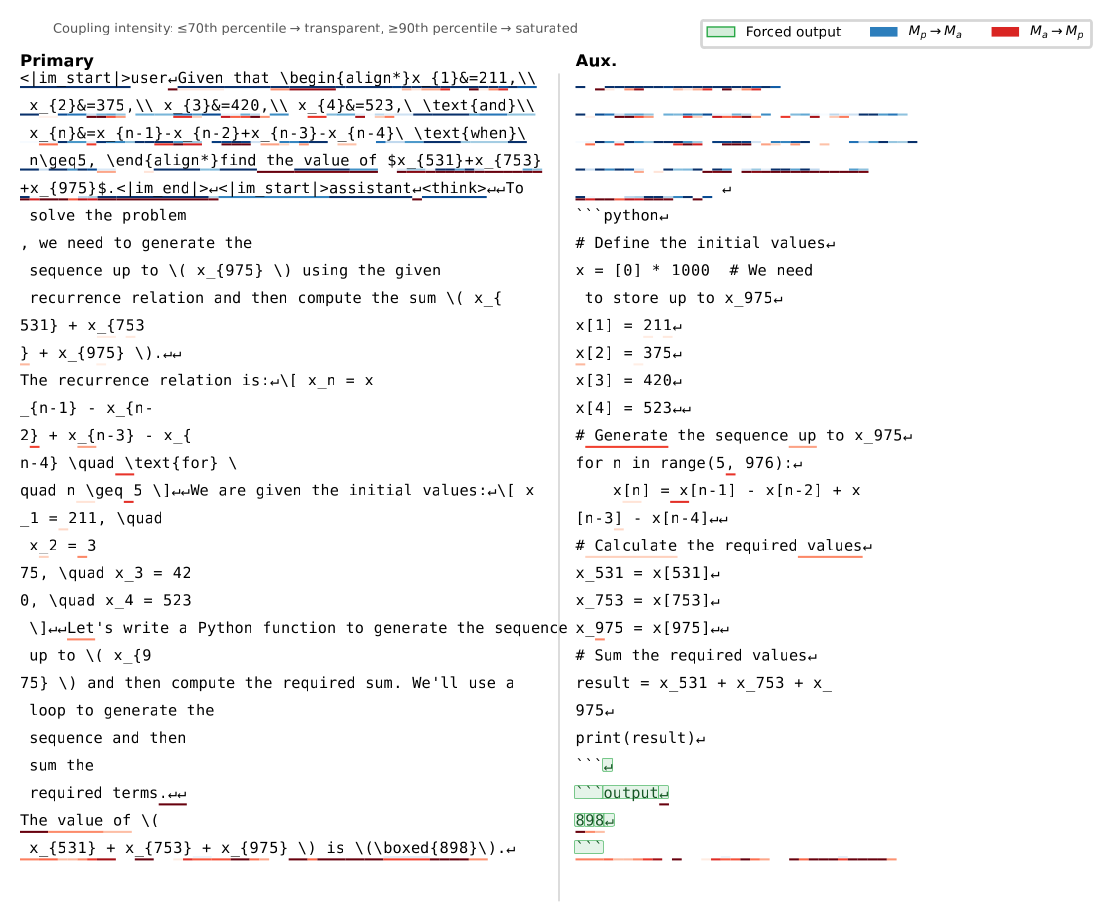
The full trace behind that program (twin Qwen3-4B, Python tool). The primary’s stream is on the left, working the problem in words; the auxiliary’s is on the right, emitting the Python that solves it. The auxiliary never reads the question: every initial value, the recurrence, and the three target indices reach it only through the forward channel (blue). When its program runs, the result flows back to the primary through the reverse channel (red) at the forced-output tokens (green).
And on 127 problems across the MATH benchmark, the coupled pair reaches an answer the lone model never finds on its own.
Watching a thought cross the bridge
Because we never specify what the bridge should carry, the natural question is what does it actually learn to send? The interface has a learned suppression gate on each direction, a little network that outputs a value $\sigma \in [0, 1]$ setting how much of the incoming signal to admit at each token. It is called a suppression gate because it starts shut, admitting nothing, and has to learn when to open. Plotting that gate over a generation turns out to be a window into the protocol the models invented.
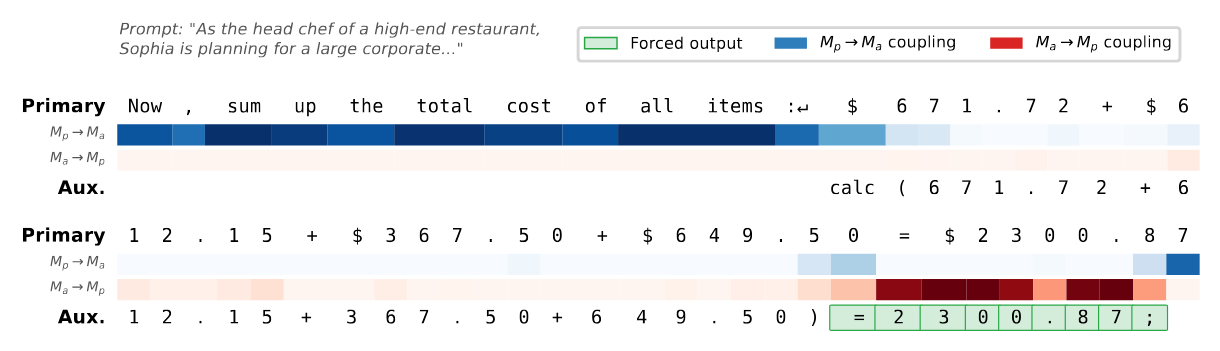
A thought crossing the bridge, token by token, on a multi-step word problem (the primary’s stream on top, the auxiliary’s below). Blue is forward coupling ($M_p to M_a$); red is reverse ($M_a to M_p$); green marks the calculator’s forced result. Forward coupling lights up on the task-shaping words (“sum,” “total,” “cost,” “all items”) but stays quiet on the dollar amounts, because the auxiliary already received those earlier and doesn’t need them repeated. Reverse coupling is near silent until the calculator returns =2300.87, at which moment it spikes and the answer flows back into the primary.
The gate was trained only to lower the task loss, and it converged on a selective, directional, surprisingly sensible protocol: send the structure of what you want computed forward, stay quiet about values the other model already has, and open the reverse channel exactly when a result is ready to come home. It even suppresses the forward signal on the numbers it knows are redundant. The channel learned what not to say, which is half of good communication.

The same protocol over a whole problem. The earlier figure was a zoomed excerpt of this full trace: a five-step restaurant word problem, with the primary’s stream on the left and the auxiliary’s on the right. The auxiliary waits, emitting filler tokens, until the primary reaches each quantity, then fires a calc(...) call; the result is forced back (green) and pulled across the reverse channel (red) right when the primary needs it. Forward coupling (blue) stays busy on the task words and quiet on the numbers the auxiliary already holds.
Do not disturb
There is a design choice buried in that gate that makes for a cute little result, and it has a nice everyday analog.
That same suppression gate can be wired two ways. You can let the receiver own it. The model being written into decides, from its own current state, how much external signal to let in. We call that a pull gate. I check my messages when I have a free moment for them. Or you can let the sender own it. The model with something to say decides when to force it across. That is a push gate. Every message I send you sets off a blaring alarm and yanks your attention off whatever you were doing.
We built the system around pull, and the receiver-controlled gate is what learns those clean, interpretable patterns above. In informal experiments the pull design also simply worked better than the corresponding push design, and the reason is the same reason it works better at the office. If you shove a thought into a model at the exact moment it is in the middle of something delicate, you degrade it, even when the thought is correct and would have been helpful a moment later. Interruption is costly independent of the value of the interruption. The receiver is the only one who knows whether right now is a good time, so the receiver should hold the gate.
File it under “suggestive anecdote with a satisfying explanation” rather than “proven law,” but I have thought about my own Slack notifications a lot more since.
How the neural channel develops
One last result, because the training dynamics reveal that the neural bridge comes online in distinct stages. If you watch the coupling come alive over training, it does not fade in smoothly. It arrives in a strict, almost developmental order, and accuracy shows up as a sharp phase transition rather than a gentle climb.
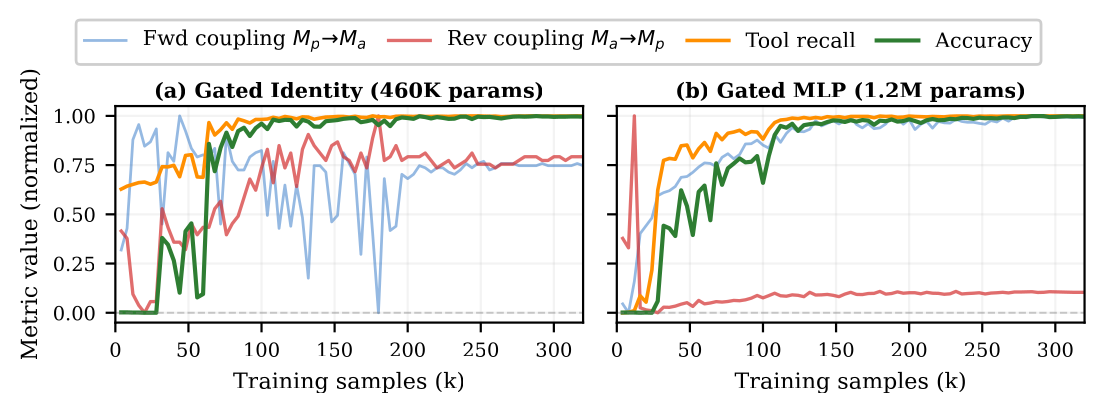
Communication switching on during training. Forward coupling (the primary teaching the auxiliary about the task) activates almost immediately. Tool recall (the auxiliary calling the calculator with the right numbers) ramps up next. Accuracy sits flat at zero for tens of thousands of samples and then jumps, once tool recall crosses a threshold. The order is causal: you cannot get the answer right until the tool is being called right, and the tool cannot be called right until the task has crossed the bridge.
The system spends a long time looking like it is learning nothing, and then snaps into competence. The capability has to be plumbed before it can be used. First the task description has to reach the auxiliary, then the auxiliary has to learn to act on it, and only then can the result find its way back and lift the score. Watching a communication channel bootstrap itself from task loss alone, in the right order, with no supervision telling it that order? These are the little gems I enjoy uncovering in AI research.
Where this could go
Everything above is two models and one bridge. The architecture does not actually care about that “two,” and that is where it starts to get fun to speculate.
A hive of models. Nothing about the interface requires the two ends to be the same size; we already ran asymmetric pairings (a large primary coupled to a small auxiliary). Push that further and you get something like a hive mind, one large primary model thought-coupled to a swarm of small specialist workers (one for code, one for search, one for a database, one for arithmetic), each whispering into the primary’s hidden state exactly when its specialty is relevant, and the primary orchestrating them all without ever rendering any of it into text. A mixture-of-experts where the experts are entire models running their own reasoning loops and tools.
A window into intentions. Run the bridge in only one direction and you get something I think matters for AI safety. Imagine a unidirectional channel from a powerful primary model into an independent monitor model whose only job is to read the primary’s hidden state and narrate, in plain tokens, what the primary appears to be trying to do. The primary cannot see the monitor and cannot shape what it says; the monitor just watches and reports. We have already shown the reverse channel can carry the structure of a computation the receiver never saw in words, so in principle a monitor could surface intentions that the primary itself never verbalizes. A faithful observer reading thoughts off the wire and writing them down in the clear would be a concrete, if early, step toward scalable oversight, or more precisely toward the AI transparency and monitoring that would help make it possible.
Models that don’t share a language. The most far-out direction, and maybe the most useful. Because the channel is sub-symbolic, the two ends do not need a common vocabulary, or any vocabulary at all. You could couple an ordinary LLM controller to a model trained entirely on genomic sequences, two systems whose “languages” have no overlap whatsoever, and still pass useful signal between them through a learned interface. You could couple a primary model to a giant neural knowledge store (a learned knowledge graph or some other mass neural memory) so that relevant facts surface into the primary’s hidden state based on what it is currently thinking about, a kind of retrieval that happens below the level of a query string. A shared neural pool of knowledge that many models read from and write to, addressed by thought rather than by text. We do not know that any of this works. But the architecture says it should be allowed to, and that would be pretty sweet.
Thinking together
It’s impressive how little we had to impose. We froze two models, dropped a small untrained bridge between them, and asked only that the pair get the task right. From that, the two of them worked out what to say to each other, when to say it, and when to stay quiet. The result is a private protocol, in a medium that never becomes words, that we can read off the gate after the fact like a transcript of a conversation neither model could have had out loud.
There is a lot here we have only scratched. The full details, experiments, and a fair accounting of what does and doesn’t work are in our paper on arXiv, where all the figures above come from too.
I will end on the connection I keep turning over. Jaynes’ bicameral humans did not experience their decisions as their own. In the hard moments the answer simply arrived, a voice with no findable source, and they acted upon it. Our primary model is bicameral in just that sense, giving the right answer while the reasoning behind it reaches it wordlessly, from a companion it has no way to know is there. Jaynes thought the bicameral mind was the stage that came before consciousness, the thing that had to break down before an inner voice could become your own. Westworld borrowed the same idea for its maze, where a host wakes up only once the voice it has been obeying turns out to be itself. I do not think we have built a mind. But if the bicameral arrangement really is the road consciousness has to travel, then maybe, in some very small way, we have set a model down at the start of the maze.